





Abstract
Methods for inference and interpretation of evolutionary quantitative genetic parameters, and for prediction of the response to selection, are best developed for traits with normal distributions. Many traits of evolutionary interest, including many life history and behavioral traits, have inherently nonnormal distributions. The generalized linear mixed model (GLMM) framework has become a widely used tool for estimating quantitative genetic parameters for nonnormal traits. However, whereas GLMMs provide inference on a statistically convenient latent scale, it is often desirable to express quantitative genetic parameters on the scale upon which traits are measured. The parameters of fitted GLMMs, despite being on a latent scale, fully determine all quantities of potential interest on the scale on which traits are expressed. We provide expressions for deriving each of such quantities, including population means, phenotypic (co)variances, variance components including additive genetic (co)variances, and parameters such as heritability. We demonstrate that fixed effects have a strong impact on those parameters and show how to deal with this by averaging or integrating over fixed effects. The expressions require integration of quantities determined by the link function, over distributions of latent values. In general cases, the required integrals must be solved numerically, but efficient methods are available and we provide an implementation in an R package, QGglmm. We show that known formulas for quantities such as heritability of traits with binomial and Poisson distributions are special cases of our expressions. Additionally, we show how fitted GLMM can be incorporated into existing methods for predicting evolutionary trajectories. We demonstrate the accuracy of the resulting method for evolutionary prediction by simulation and apply our approach to data from a wild pedigreed vertebrate population.
ADDITIVE genetic variances and covariances of phenotypic traits determine the response to selection and so are key determinants of the processes of adaptation in response to natural selection and of genetic improvement in response to artificial selection (Fisher 1918; Falconer 1960; Lynch and Walsh 1998; Walsh and Lynch 2003). While the concept of additive genetic variance (Fisher 1918; Falconer 1960) is very general, being applicable to any type of character with any arbitrary distribution, including, for example, fitness (Fisher 1930), techniques for estimating additive genetic variances and covariances are best developed for Gaussian traits [i.e., traits that follow a normal distribution (Henderson 1950; Lynch and Walsh 1998)]. Furthermore, quantitative genetic theory for predicting responses to selection is also best developed and established for Gaussian characters (Walsh and Lynch 2003; but see Morrissey 2015). Consequently, although many characters of potential evolutionary interest are not Gaussian (e.g., survival or number of offspring), they are not well handled by existing theory and methods. Comprehensive systems for estimating genetic parameters and predicting evolutionary trajectories of non-Gaussian traits will hence be very useful for quantitative genetic studies of adaptation.
For the analysis of Gaussian traits, linear mixed model (LMM)-based inferences of genetic parameters, using the “animal model,” have become common practice in animal and plant breeding (Thompson 2008; Hill and Kirkpatrick 2010), but also in evolutionary studies on wild populations (Kruuk 2004; Wilson et al. 2010). Recently, the use of generalized linear mixed models (GLMMs) to analyze non-Gaussian traits has been increasing (e.g., Milot et al. 2011; Wilson et al. 2011; Morrissey et al. 2012; de Ayers et al. 2013; Villemereuil et al. 2013). Whereas LMM analysis directly estimates additive genetic parameters on the scale on which traits are expressed and selected, and upon which we may most naturally consider their evolution, this is not the case for GLMMs. In this article, we offer a comprehensive description of the assumptions of GLMMs and their consequences in terms of quantitative genetics and a framework to infer quantitative genetic parameters from GLMMs output. This work applies and extends theory in Morrissey (2015), to handle the effects of (nonlinear) relationships among the scale upon which inference is conducted in a GLMM and the scale of data and to accommodate the error structures that arise in GLMM analysis. These results generalize existing expressions for specific models [threshold model and Poisson with a log link (Dempster and Lerner 1950; Robertson 1950; Foulley and Im 1993)]. We show that fixed effects in GLMMs raise special complications and we offer some efficient approaches for dealing with this issue.
While it will undoubtedly be desirable to develop a comprehensive method for making data-scale inferences of quantitative genetic parameters with GLMMs, such an endeavor will not yield a system for predicting evolution in response to natural or artificial selection, even if a particular empirical system is very well served by the assumptions of a GLMM. This is because systems for evolutionary prediction, specifically the breeder’s equation (Fisher 1924; Lush 1937) and the Lande equation (Lande 1979; Lande and Arnold 1983), assume that breeding values (and in most applications, phenotypes) are multivariate normal or make assumptions such as linearity of the parent–offspring regression, which are unlikely to hold for nonnormal traits (Walsh and Lynch 2003). Even if it is possible to estimate additive genetic variances of traits on the scale upon which traits are expressed, we show that these quantities are not strictly usable for evolutionary prediction. However, we will see that the scale on which estimation is performed in a GLMM does, by definition, satisfy the assumptions of the breeder’s and Lande equations. Thus, for the purpose of predicting evolution, it may be useful to be able to express selection of non-Gaussian traits on this scale. Such an approach will yield a system for evolutionary prediction of characters that have been modeled with a GLMM, requiring no more assumptions than those that are already made in applying the statistical model.
The main results in this article are arranged in four sections. First, we describe the GLMM framework: its relationship to the more general (Gaussian) LMM and especially to the Gaussian animal model (Henderson 1973; Kruuk 2004; Wilson et al. 2010), how GLMMs can be usefully viewed as covering three scales, and how some special interpretational challenges arise and are currently dealt with. Second, we propose a system for making inferences of quantitative genetic parameters on the scale upon which traits are expressed for arbitrary GLMMs. We show how to estimate genotypic and additive genetic variances and covariances on this scale, accounting for fixed effects as necessary. We lay out the formal theory underlying the system and apply it to an empirical data set. The relationships between existing analytical formulas and our general framework are also highlighted. Third, we illustrate the issues when inferring quantitative genetic parameters using a GLMM with an empirical example on Soay sheep (Ovis aries) and how our framework can help to overcome them. Fourth, we outline a system of evolutionary prediction for non-Gaussian traits that capitalizes on the fact that the latent scale in a GLMM satisfies the assumptions of available equations for the prediction of evolution. We show in a simulation study that (i) evolutionary predictions using additive genetic variances on the observed data scale represent approximations and can, in fact, give substantial errors, and (ii) making inferences via the latent scale provides unbiased predictions, insofar as a GLMM may provide a pragmatic model of variation in non-Gaussian traits. The framework introduced here (including both quantitative genetic parameter inference and evolutionary prediction) has been implemented in an R package (R Core Team 2015), QGglmm, and is available at https://cran.r-project.org/.
The Generalized Linear Mixed Model Framework
Linear mixed models for Gaussian traits
Common issues with non-Gaussian traits
Many non-Gaussian traits, however, cannot be strictly additive on the scale on which they are expressed. Consider, for example, survival probability that is bounded at 0 and 1 so that effects like the substitution effect of one allele for another necessarily must be smaller when expressed in individuals that otherwise have expected values near 0 or 1. In such a scenario, it may be reasonable to assume that there exists an underlying scale, related to survival probability, upon which genetic and other effects are additive.
In addition to inherent nonadditivity, many non-Gaussian traits will have complex patterns of variation. Over and above sources of variation that can be modeled with fixed and random effects, as in an LMM (e.g., using Equations 1 and 2), residual variation may include both inherently stochastic components and components that correspond to unmodeled systematic differences among observations. In an LMM, such differences are not distinguished, but contribute to residual variance. However, for many non-Gaussian traits it may be desirable to treat the former as arising from some known statistical distribution, such as the binomial or Poisson distribution, and to deal with additional variation via a latent-scale residual (i.e., an overdispersion term). Separation of these two kinds of variation in residuals may be very generally useful in evolutionary quantitative genetic studies.
The scales of the generalized linear mixed model
GLMM analysis can be used for inference of quantitative genetic parameters and provides pragmatic ways of dealing with inherent nonadditivity and with complex sources of variation. The GLMM framework can be thought of as consisting of three distinct scales on which we can think of variation in a trait occurring (see Figure 1). A latent scale is assumed (Figure 1, top), on which effects on the propensity for expression of some trait are assumed to be additive. A function, called a “link function,” is applied that links expected values for a trait to the latent scale. For example, a trait that is expressed in counts, say, number of behaviors expressed in a unit time, is a strictly nonnegative quantity. As depicted in Figure 1, a strictly positive distribution of expected values may be related to latent values ranging from to by a function such as the log link. Finally, a distribution function (e.g., binomial, Poisson, etc.) is required to model the “noise” of observed values around the expected value (Figure 1, bottom). Different distributions are suitable for different traits. For example, with a count trait such as that depicted in Figure 1, observed values may be modeled using the Poisson distribution, with expectations related to the latent scale via the log-link function.
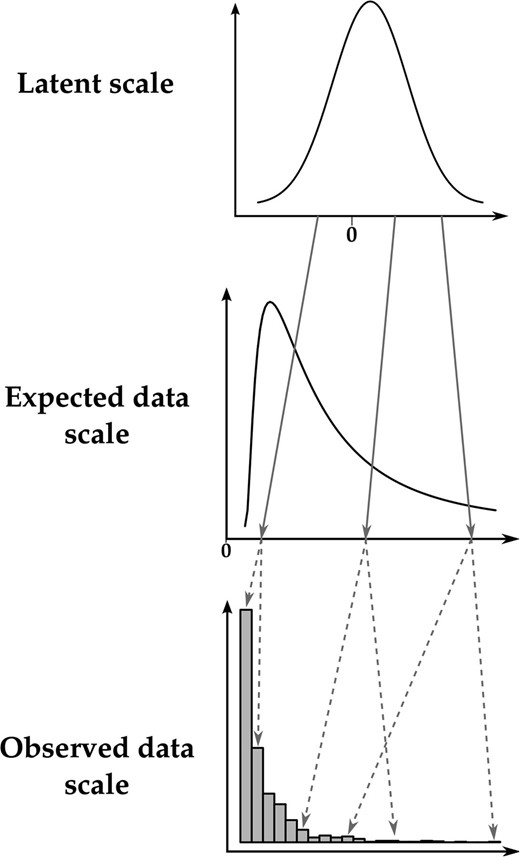
Example of the relationships between the three scales of the GLMM using a Poisson distribution and a logarithm-link function. Deterministic relationships are denoted with shaded solid arrows, whereas stochastic relationships are denoted with shaded dashed arrows. Note that the latent scale is depicted as a simple Gaussian distribution for the sake of simplicity, whereas it is a mixture of Gaussian distributions in reality.
Equation 3b formalizes the idea of the link function. Any link function has an associated inverse link function, , which is often useful for converting specific latent values to expected values. The expected values constitute what we call the expected data scale. For example, where the log-link function translates expected values to the latent scale, its inverse, the exponential function, translates latent values to expected values. Finally, Equation 3c specifies the distribution by which the observations scatter around the expected values according to some distribution function that may involve parameters (denoted ) other than the expectation. We call this the observed data scale. Some quantities of interest, such as the mean, are the same on the expected data scale and on the observed data scale. When parameters are equivalent on these two scales, we refer to them together as the data scales.
The distinction we make between the expected and observed data scales is one of convenience as they are not different scales per se. However, this distinction allows for more biological subtlety when interpreting the output of a GLMM. The expected data scale can be thought of as the “intrinsic” value of individuals (shaped by both genes and the environment), but this intrinsic value can be studied only through random realizations. As we will see, because breeding values are intrinsic individual values, the additive genetic variance is the same for both scales, but, due to the added noise in observed data, the heritabilities are not. The choice of which scale to calculate heritability depends on the underlying biological question. For example, individuals (given their juvenile growth and genetic value) might have an intrinsic annual reproductive success of 3.4, but can produce only an integer number of offspring each year (say 2, 3, 4, or 5): Heritabilities of both intrinsic expectations and observed numbers can be computed, but their values and interpretations will differ.
Current practices and issues with computing quantitative genetic parameters from GLMM outputs
In addition to handling the relationship between observed data and the latent trait via the link and distribution functions, any system for expected and observed scale quantitative genetic inference with GLMMs will have to account for complex ways in which fixed effects can influence quantitative genetic parameters. It is currently appreciated that fixed effects in LMMs explain variance and that variance associated with fixed effects can have a large influence on summary statistics such as repeatability (Nakagawa and Schielzeth 2010) and heritability (Wilson 2008). This principle holds for GLMMs as well, but fixed effects cause additional, important complications for interpreting GLMMs. While random and fixed effects are independent in a GLMM on the latent scale, the nonlinearity of the link function renders them interrelated on the expected and observed scales. Consequently, and unlike in an LMM or in a GLMM on the latent scale, variance components on the observed scale in a GLMM depend on the fixed effects. Consider, for example, a GLMM with a log-link function. Because the exponential is a convex function, the influence of fixed and random effects will create more variance on the expected and observed data scales for larger values than for smaller values.
Quantitative Genetic Parameters in GLMMs
Although all examples and most equations in this article are presented in a univariate form, all our results are applicable to multivariate analysis, which is implemented in our software. Unless stated otherwise, the equations below assume that no fixed effects (apart from the intercept) were included in the GLMM model.
Phenotypic mean and variances
Expected population mean:
Expected-scale phenotypic variance:
Phenotypic variance on the expected data scale can be obtained analogously to the data scale population mean. Having obtained , the phenotypic variance is
Observed-scale phenotypic variance:
Phenotypic variance of observed values is the sum of the variance in expected values and variance arising from the distribution function. Since these variances are independent by construction in a GLMM, they can be summed. This distribution variance is influenced by the latent trait value, but might also depend on additional distribution parameters included in (see Equation 3c). Given a distribution-specific variance function v,
Genotypic variance on the data scales, arising from additive genetic variance on the latent scale
Additive genetic variance on the data scales
Including fixed effects in the inference
General issues:
Because of the nonlinearity introduced by the link function in a GLMM, all quantitative genetic parameters are directly influenced by the presence of fixed effects. Hence, when fixed effects are included in the model, it will often be important to marginalize over them to compute accurate population parameters. There are different approaches to do so. We first describe the simplest approach (i.e., directly based on GLMM assumptions).
Averaging over predicted values:
Sampled covariates are not always representative of the population:
Summary statistics and multivariate extensions
Relationships with existing analytical formulas
Binomial distribution and the threshold model:
Poisson distribution with a logarithm link:
Example Analysis: Quantitative Genetic Parameters of a Nonnormal Character
We modeled the first-year survival of Soay sheep (O. aries) lambs on St. Kilda, Outer Hebrides, Scotland. We analyzed records of 3814 individuals born between 1985 and 2001 that are known to either have died in their first year, defined operationally as having died before the first of April in the year following their birth, or have survived beyond their first year. Months of mortality for sheep of all ages are generally known from direct observation, and day of mortality is typically known. Furthermore, every lamb included in this analysis had a known sex and twin status (whether or not it had a twin) and a mother of a known age.
Pedigree information is available for the St. Kilda Soay sheep study population. Maternal links are known from direct observation, with occasional inconsistencies corrected with genetic data. Paternal links are known from molecular data. Most paternity assignments are made with very high confidence, using a panel of 384 SNP markers, each with high minor allele frequencies, and spread evenly throughout the genome. Details of marker data and pedigree reconstruction are given in Bérénos et al. (2014). The pedigree information was pruned to include only phenotyped individuals and their ancestors. The pedigree used in our analyses thus included 4687 individuals with 4165 maternal links and 4054 paternal links.
We fitted a generalized linear mixed model of survival with a logit-link function and a binomial distribution function. We included fixed effects of individual’s sex and twin status and linear, quadratic, and cubic effects of maternal age (). Maternal age was mean centered by subtracting the overall mean. We also included an interaction of sex and twin status and an interaction of twin status with maternal age. We included random effects of breeding value (as for Equation 2), maternal identity, and birth year. Because the overdispersion variance in a binomial GLMM is unobservable for binary data, we set its variance to one. The model was fitted in MCMCglmm (Hadfield 2010), with diffuse independent normal priors on all fixed effects and parameter-expanded priors for the variances of all estimated random effects.
We identified important effects on individual survival probability; i.e., several fixed effects were substantial and also each of the additive genetic, maternal, and among-year random effects explained appreciable variance (Table 1). The model intercept corresponds to the expected value on the latent scale of a female singleton (i.e., not a twin) lamb with an average-aged (4.8 years) mother. Males have lower survival than females, and twins have lower survival than singletons. There were also substantial effects of maternal age, corresponding to a rapid increase in lamb survival with maternal age among relatively young mothers and a negative curvature, such that the maximum survival probabilities occur among offspring of mothers aged 6 or 7 years. The trajectories of maternal age effects in the cubic model are similar to those obtained when maternal age is fitted as a multilevel effect.
Parameters from the GLMM-based quantitative genetic analysis of Soay sheep (O. aries) lamb first-year survival
| Parameter | Posterior mode with 95% CI |
|---|---|
| Fixed effects | |
| Intercept | 2.573 (1.755–3.514) |
| Sex (male vs. female) | −1.193 (−1.441 to −0.943) |
| Twin (twin vs. singleton) | −2.567 (−3.377 to −1.754) |
| Maternal age, linear term | 0.233 (0.089–0.390) |
| Maternal age, quadratic term | −0.171 (−0.194 to −0.148) |
| Maternal age, cubic term | 0.014 (0.010–0.020) |
| Sex–twin interaction | 0.543 (0.015–1.068) |
| Sex–maternal age interaction | −0.026 (−0.114 to 0.054) |
| Random effects | |
| 0.915 (0.275–1.664) | |
| 0.520 (0.177–0.887) | |
| 3.335 (1.452–5.551) | |
| Parameter | Posterior mode with 95% CI |
|---|---|
| Fixed effects | |
| Intercept | 2.573 (1.755–3.514) |
| Sex (male vs. female) | −1.193 (−1.441 to −0.943) |
| Twin (twin vs. singleton) | −2.567 (−3.377 to −1.754) |
| Maternal age, linear term | 0.233 (0.089–0.390) |
| Maternal age, quadratic term | −0.171 (−0.194 to −0.148) |
| Maternal age, cubic term | 0.014 (0.010–0.020) |
| Sex–twin interaction | 0.543 (0.015–1.068) |
| Sex–maternal age interaction | −0.026 (−0.114 to 0.054) |
| Random effects | |
| 0.915 (0.275–1.664) | |
| 0.520 (0.177–0.887) | |
| 3.335 (1.452–5.551) | |
All estimates are reported as posterior modes with 95% credible intervals (CI). The intercept in this model is arbitrarily defined for female lambs without twins, born to average-aged (4.8 years) mothers.
| Parameter | Posterior mode with 95% CI |
|---|---|
| Fixed effects | |
| Intercept | 2.573 (1.755–3.514) |
| Sex (male vs. female) | −1.193 (−1.441 to −0.943) |
| Twin (twin vs. singleton) | −2.567 (−3.377 to −1.754) |
| Maternal age, linear term | 0.233 (0.089–0.390) |
| Maternal age, quadratic term | −0.171 (−0.194 to −0.148) |
| Maternal age, cubic term | 0.014 (0.010–0.020) |
| Sex–twin interaction | 0.543 (0.015–1.068) |
| Sex–maternal age interaction | −0.026 (−0.114 to 0.054) |
| Random effects | |
| 0.915 (0.275–1.664) | |
| 0.520 (0.177–0.887) | |
| 3.335 (1.452–5.551) | |
| Parameter | Posterior mode with 95% CI |
|---|---|
| Fixed effects | |
| Intercept | 2.573 (1.755–3.514) |
| Sex (male vs. female) | −1.193 (−1.441 to −0.943) |
| Twin (twin vs. singleton) | −2.567 (−3.377 to −1.754) |
| Maternal age, linear term | 0.233 (0.089–0.390) |
| Maternal age, quadratic term | −0.171 (−0.194 to −0.148) |
| Maternal age, cubic term | 0.014 (0.010–0.020) |
| Sex–twin interaction | 0.543 (0.015–1.068) |
| Sex–maternal age interaction | −0.026 (−0.114 to 0.054) |
| Random effects | |
| 0.915 (0.275–1.664) | |
| 0.520 (0.177–0.887) | |
| 3.335 (1.452–5.551) | |
All estimates are reported as posterior modes with 95% credible intervals (CI). The intercept in this model is arbitrarily defined for female lambs without twins, born to average-aged (4.8 years) mothers.
To illustrate the consequences of accounting for different fixed effects on expected and observed data scale inferences, we calculated several parameters under a series of different treatments of the latent scale parameters of the GLMM. We calculated the phenotypic mean, the additive genetic variance, the total variance of expected values, the total variance of observed values, and the heritability of survival on the expected and observed scales.
First, we calculated parameters using only the model intercept (μ in Equations 1 and 3a). This intercept, under default settings, is arbitrarily defined by the linear modeling software implementation and is thus software dependent. In the current case, due to the details of how the data were coded, the intercept is the latent scale prediction for female singletons with average-aged (4.8 years) mothers. In an average year, singleton females with average-aged mothers have a probability of survival of ∼80%. The additive genetic variance , calculated with Equation 16, is ∼0.005 and corresponds to heritabilities on the expected and observed scales of 0.096 and 0.051 (Table 2).
Estimates of expected and observed scale phenotypic mean and variances and additive genetic variance, for three different treatments of the fixed effects modeled on the linear scale with a GLMM and reported in Table 1
| Quantity | Arbitrary intercept (singleton female) | Arbitrary intercept (twin male) | Averaging over all fixed effects |
|---|---|---|---|
| 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | |
| 0.152 (0.056–0.270) | 0.152 (0.056–0.270) | 0.111 (0.042–0.194) | |
| 0.788 (0.718–0.886) | 0.371 (0.212–0.471) | 0.430 (0.336–0.517) | |
| 0.006 (0.002–0.015) | 0.011 (0.005–0.024) | 0.014 (0.005–0.021) | |
| 0.062 (0.033–0.096) | 0.104 (0.069–0.123) | 0.120 (0.106–0.138) | |
| 0.167 (0.107–0.206) | 0.241 (0.183–0.250) | 0.250 (0.226–0.250) | |
| 0.096 (0.036–0.202) | 0.125 (0.045–0.227) | 0.112 (0.036–0.170) | |
| 0.051 (0.015–0.085) | 0.048 (0.023–0.106) | 0.047 (0.019–0.089) |
| Quantity | Arbitrary intercept (singleton female) | Arbitrary intercept (twin male) | Averaging over all fixed effects |
|---|---|---|---|
| 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | |
| 0.152 (0.056–0.270) | 0.152 (0.056–0.270) | 0.111 (0.042–0.194) | |
| 0.788 (0.718–0.886) | 0.371 (0.212–0.471) | 0.430 (0.336–0.517) | |
| 0.006 (0.002–0.015) | 0.011 (0.005–0.024) | 0.014 (0.005–0.021) | |
| 0.062 (0.033–0.096) | 0.104 (0.069–0.123) | 0.120 (0.106–0.138) | |
| 0.167 (0.107–0.206) | 0.241 (0.183–0.250) | 0.250 (0.226–0.250) | |
| 0.096 (0.036–0.202) | 0.125 (0.045–0.227) | 0.112 (0.036–0.170) | |
| 0.051 (0.015–0.085) | 0.048 (0.023–0.106) | 0.047 (0.019–0.089) |
Additive genetic variance and heritability on the latent scales are also reported for comparison. Note that is slightly lower when averaging over fixed effects, since the variance they explain is then accounted for.
| Quantity | Arbitrary intercept (singleton female) | Arbitrary intercept (twin male) | Averaging over all fixed effects |
|---|---|---|---|
| 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | |
| 0.152 (0.056–0.270) | 0.152 (0.056–0.270) | 0.111 (0.042–0.194) | |
| 0.788 (0.718–0.886) | 0.371 (0.212–0.471) | 0.430 (0.336–0.517) | |
| 0.006 (0.002–0.015) | 0.011 (0.005–0.024) | 0.014 (0.005–0.021) | |
| 0.062 (0.033–0.096) | 0.104 (0.069–0.123) | 0.120 (0.106–0.138) | |
| 0.167 (0.107–0.206) | 0.241 (0.183–0.250) | 0.250 (0.226–0.250) | |
| 0.096 (0.036–0.202) | 0.125 (0.045–0.227) | 0.112 (0.036–0.170) | |
| 0.051 (0.015–0.085) | 0.048 (0.023–0.106) | 0.047 (0.019–0.089) |
| Quantity | Arbitrary intercept (singleton female) | Arbitrary intercept (twin male) | Averaging over all fixed effects |
|---|---|---|---|
| 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | 0.915 (0.275–1.664) | |
| 0.152 (0.056–0.270) | 0.152 (0.056–0.270) | 0.111 (0.042–0.194) | |
| 0.788 (0.718–0.886) | 0.371 (0.212–0.471) | 0.430 (0.336–0.517) | |
| 0.006 (0.002–0.015) | 0.011 (0.005–0.024) | 0.014 (0.005–0.021) | |
| 0.062 (0.033–0.096) | 0.104 (0.069–0.123) | 0.120 (0.106–0.138) | |
| 0.167 (0.107–0.206) | 0.241 (0.183–0.250) | 0.250 (0.226–0.250) | |
| 0.096 (0.036–0.202) | 0.125 (0.045–0.227) | 0.112 (0.036–0.170) | |
| 0.051 (0.015–0.085) | 0.048 (0.023–0.106) | 0.047 (0.019–0.089) |
Additive genetic variance and heritability on the latent scales are also reported for comparison. Note that is slightly lower when averaging over fixed effects, since the variance they explain is then accounted for.
In contrast, if we wanted to calculate parameters using a different (but equally arbitrary) intercept, corresponding to twin males, we would obtain a mean survival rate of 0.37 and an additive genetic variance that is approximately twice as large, but similar heritabilities (Table 1). Note that we have not modeled any systematic differences in genetic parameters between females and males or between singletons and twins. These differences in parameter estimates arise from the exact same estimated variance components on the latent scale, as a result of different fixed effects.
This first comparison has illustrated a major way in which the fixed effects in a GLMM influence inferences on the expected and observed data scales. For linear mixed models, it has been noted that variance in the response is explained by the fixed predictors and that this may inappropriately reduce the phenotypic variance and inflate heritability estimates for some purposes (Wilson 2008). However, in the example so far, we have simply considered two different intercepts (i.e., no difference in explained variance): female singletons vs. male twins, in both cases, assuming focal groups of individuals are all born to average-aged mothers. Again these differences in phenotypic variances and heritabilities arise from differences in intercepts, not from any differences in variance explained by fixed effects. All parameters on the expected and observed value scales are dependent on the intercept, including the mean, the additive genetic variance, and the total variance generated from random effects. Heritability is modestly affected by the intercept, because additive genetic and total variances are similarly, but not identically, influenced by the model intercept.
Additive genetic effects are those arising from the average effect of alleles on phenotype, integrated over all background genetic and environmental circumstances in which alternate alleles might occur. Fixed effects, where they represent biologically relevant variation, are part of this background. Following our framework (see Equation 17), we can solve the issue of the influence of the intercept by integrating our calculation of and ultimately over all fixed effects. This approach has the advantage of being consistent for any chosen intercept, as the value obtained after integration will not depend on that intercept. Considering all fixed and random effects, quantitative genetic parameters on the expected and observed scales are given in Table 2, fourth column. Note that additive genetic variance is not intermediate between the two extremes (concerning sex and twin status) that we previously considered. The calculation of now includes an average slope calculated over a wide range of the steep part of the inverse-link function (near 0 on the latent scale and near 0.5 on the expected data scale) and so is relatively high. The observed total phenotypic variance is also quite high. The increase in has two causes. First, the survival mean is closer to 0.5, so the random effects variance is now manifested as greater total variance on the expected and observed scales. Second, there is now variance arising from fixed effects that is included in the total variance.
Given this, which estimates should be reported or interpreted? We have seen that when fixed effects are included in a GLMM, the quantitative genetic parameters calculated without integration are sensitive to an arbitrary parameter: the intercept. Hence integration over fixed effects may often be the best strategy for obtaining parameters that are not arbitrary. In the case of survival analyzed here, is the heritability of realized survival, whereas is the heritability of intrinsic individual survival. Since realized survival is the one “visible” by natural selection, might be a more relevant evolutionary parameter. Nonetheless, we recommend that and are both reported.
Data availability
The data analyzed (individual identity, first year survival, maternal identity and all covariates, and the pedigree) in this example are archived and available via the following DOI: 10.17605/OSF.IO/SCZPR.
Evolutionary Prediction
Systems for predicting adaptive evolution in response to phenotypic selection assume that the distribution of breeding values is multivariate normal and, in most applications, that the joint distribution of phenotypes and breeding values is multivariate normal (Lande 1979; Lande and Arnold 1983; Walsh and Lynch 2003; Morrissey 2014). The distribution of breeding values is assumed to be normal on the latent scale in a GLMM analysis, and therefore the parent–offspring regression will also be normal on that scale, but not necessarily on the data scale. Consequently, evolutionary change predicted directly using data-scale parameters may be distorted. The breeder’s and Lande equations may hold approximately and may perhaps be useful. However, having taken up the nontrivial task of pursuing GLMM-based quantitative genetic analysis, the investigator has at his or her disposal inferences on the latent scale. On this scale, the assumptions required to predict the evolution of quantitative traits hold. In this section we first demonstrate by simulation how application of the breeder’s equation will generate biased predictions of evolution. We then proceed to an exposition of some statistical machinery that can be used to predict evolution on the latent scale (from which evolution on the expected and observed scale can subsequently be calculated, using Equation 5), given inference of the function relating traits to fitness.
Direct application of the breeder’s and Lande equations on the data scale
To explore the predictions of the breeder’s equation applied at the level of observed phenotype, we conducted a simulation in which phenotypes were generated according to a Poisson GLMM (Equations 3a–3c, with a Poisson distribution function and a log-link function) and then selected the largest observed count values (positive selection) with a range of proportions of selected individuals (from 5% to 95%, creating a range of selection differentials), a range of latent-scale heritabilities (0.1, 0.3, 0.5, and 0.8, with a latent phenotypic variance fixed to 0.1), and a range of latent means μ (from 0 to 3). We simulated 10,000 replicates of each scenario, each composed of a different array of 10,000 individuals. For each simulation, we simulated 10,000 offspring. For each offspring, a breeding value was simulated according to , where is the focal offspring’s breeding value, and are the breeding values of simulated dams and sires, and represents the segregational variance, assuming parents are not inbred. Dams and sires were chosen at random with replacement from among the pool of simulated selected individuals. For each scenario, we calculated the realized selection differential arising from the simulated truncation selection, , and the average evolutionary response across simulations, . For each scenario, we calculated the heritability on the observed scale, using Equation 20. If the breeder’s equation was strictly valid for a Poisson GLMM on the observed scale, the realized heritability would be equal to the observed-scale heritability .
The correspondence between and is approximate (Figure 2) and strongly depends on the selection differential (controlled here by the proportion of selected individuals). Note that, although the results presented here depict a situation where the ratio is very often larger than , this is not a general result (e.g., this is not the case when using negative instead of positive selection; data not shown). In particular, evolutionary predictions are poorest in absolute terms for large μ and large (latent) heritabilities. However, because we were analyzing simulation data, we could track the selection differential of latent values (by calculating the difference in its mean between simulated survivors and the mean simulated before selection). We can also calculate the mean latent breeding value after selection. Across all simulation scenarios, the ratio of the change in mean breeding value after selection to the change in breeding value before selection was equal to the latent heritability (see Figure 2), showing that evolutionary changes could be accurately predicted on the latent scale.
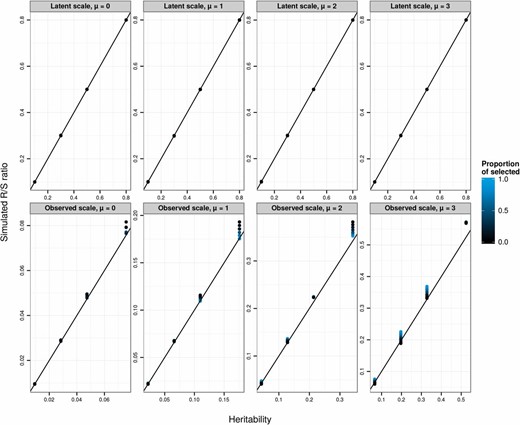
Simulated (evolutionary response over selection differential or the realized heritability) on the latent (top panels) or observed (bottom panels) data scales against the corresponding scale heritabilities. Each data point is the average over 10,000 replicates of 10,000 individuals for various latent heritabilities (0.1, 0.3, 0.5, 0.8), latent population mean (μ from 0 to 3, from left to right), and proportion of selected individuals (5%, 10%, 20%, 30%, 50%, 70%, 80%, 90%, and 95%, varying from black to blue). The 1:1 line is plotted in black. The breeder’s equation is predictive on the latent scale (top panels), but approximate on the observed data scale (bottom panels), because phenotypes and breeding values are not jointly multivariate normal on that scale.
Evolutionary change on the latent scale and associated change on the expected and observed scales
In an analysis of real data, latent (breeding) values are, of course, not measured. However, given an estimate of the effect of traits on fitness, say via regression analysis, we can derive the parameters necessary to predict evolution on the latent scale. The idea is thus to relate measured fitness on the observed data scale to the latent scale, compute the evolutionary response on the latent scale, and finally compute the evolutionary response on the observed data scale.
Another derivation of the expected evolutionary response using the Price–Robertson identity (Robertson 1966; Price 1970) is given in the File S1 (section C).
The simulation study revisited
Using the same replicates as in the simulation study above, we used Equations 29–34 to predict phenotypic evolution. This procedure provides greatly improved predictions of evolutionary change on the observed scale (Figure 3, top row). However, somewhat less response to selection is observed than is predicted. This deviation occurs because, in addition to producing a permanent evolutionary response in the mean value on the latent scale, directional selection creates a transient reduction of additive genetic variance due to linkage disequilibrium. Because the link function is nonlinear, this transient change in the variance on the latent scale generates a transient change in the mean on the expected and observed scales. Following several generations of random mating, the evolutionary change on the observed scale would converge on the predicted values. We simulated such a generation at equilibrium by simply drawing breeding values for the postselection sample from a distribution with the same variance as in the parental generation. This procedure necessarily generated a strong match between predicted and simulated evolution (Figure 3, bottom row). Additionally, the effects of transient reduction in genetic variance on the latent scale could be directly modeled, for example, using Bulmer’s (1971) approximations for the transient dynamics of the genetic variance in response to selection.
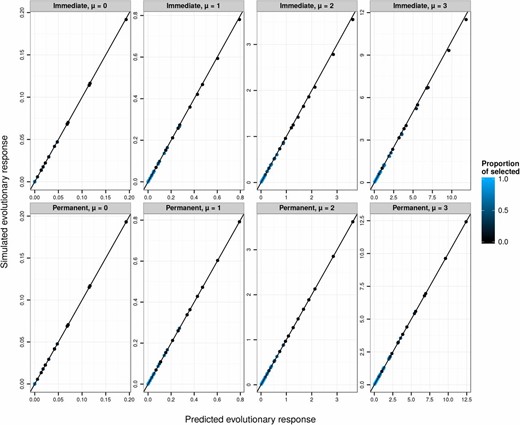
Predicted (phenotypic evolutionary response on the observed scale, see Equation 34) against the simulated , via evolutionary predictions applied on the latent scale. Each data point is the average over 10,000 replicates of 10,000 individuals for various latent heritabilities (0.1, 0.3, 0.5, 0.8), latent population mean (μ from 0 to 3), and proportion of selected individuals (5%, 10%, 20%, 30%, 50%, 70%, 80%, 90%, and 95%, varying from black to blue). The 1:1 line is plotted in black. The top panels (“Immediate”) show simulations for the response after a single generation, which include both a permanent and a transient response to selection arising from linkage disequilibrium. The bottom panels (“Permanent”) show simulation results modified to reflect only the permanent response to selection.
Implementation
The framework developed here (including univariate and multivariate parameters computation and evolutionary predictions on the observed data scale) is implemented in the R package QGglmm available via the R comprehensive archive network, https://cran.r-project.org/. The package does not perform any GLMM inference but rather implements the hereby introduced framework for analysis posterior to a GLMM inference. While the calculations we provide will often (i.e., when no analytical formula exists) be more computationally demanding than calculations on the latent scale, they will be direct ascertainments of specific parameters of interest, since the scale of evolutionary interest is likely to be the observed data scale, rather than the latent scale (unless some artificial selection is applied to predicted latent breeding values as in modern animal breeding). Most applications should not be onerous. Computations of means and (additive genetic) variances took <1 sec on a 1.7-GHz processor when using our R functions on the Soay sheep data set. Summation over fixed effects and integration over 1000 posterior samples of the fitted model took several minutes. When analytical expressions are available (e.g., for Poisson/log, binomial/probit, and negative-binomial/log, see File S1 and R package documentation), these computations are considerably accelerated.
Conclusion
The general approach outlined here for quantitative genetic inference with GLMMs has several desirable features: (i) It is a general framework, which should work with any given GLMM and especially any link and distribution function; (ii) it provides mechanisms for rigorously handling fixed effects, which can be especially important in GLMMs; and (iii) it can be used for evolutionary prediction under standard GLMM assumptions about the genetic architecture of traits.
Currently, with the increasing application of GLMMs, investigators seem eager to convert to the observed data scale. It seems clear that conversions between scales are generally useful. However, it is of note that the underlying assumption when using GLMMs for evolutionary prediction is that predictions hold on the latent scale. Hence, some properties of heritabilities for additive Gaussian traits, particularly the manner in which they can be used to predict evolution, do not hold on the data scale for non-Gaussian traits, even when expressed on the data scale. Yet, given an estimate of a fitness function, no further assumptions are necessary to predict evolution on the data scale, via the latent scale (as with Equations 29, 31, and 33), over and above those that are made in the first place upon deciding to pursue GLMM-based quantitative genetic analysis. Hence we recommend using this framework to produce accurate predictions about evolutionary scenarios.
We have highlighted important ways in which fixed effects influence quantitative genetic inferences with GLMMs and developed an approach for handling these complexities. In LMMs, the main consideration pertaining to fixed effects is that they explain variance, and some or all of this variance might be inappropriate to exclude from an assessment of when calculating heritabilities (Wilson 2008). This aspect of fixed effects is relevant to GLMMs, but furthermore, all parameters on the expected and observed scales, not just means, are influenced by fixed effects in GLMMs; these include additive genetic and phenotypic variances. This fact necessitates particular care in interpreting GLMMs. Our work clearly demonstrates that consideration of fixed effects is essential, and the exact course of action needs to be considered on a case-by-case basis. Integrating over fixed effects would solve, in particular, the issue of intercept arbitrariness illustrated with the Soay sheep example. Yet cases may often arise where fixed effects are fitted, but where one would not want to integrate over them (e.g., because they represent experimental rather than natural variability). In such cases, it will be important to work with a biologically meaningful intercept, which can be achieved for example by centering covariates on relevant values (Schielzeth 2010). Finally, note that this is not an all-or-none alternative: In some situations, it could be relevant to integrate over some fixed effects (e.g., of biological importance) while some other fixed effects (e.g., those of experimental origins) would be left aside.
One of the most difficult concepts in GLMMs seen as a nonlinear developmental model (Morrissey 2015) is that an irreducible noise is attached to the observed data. This is the reason why we believe that distinguishing between expected and observed data scales does have a biological meaning. Researchers using GLMMs need to realize that this kind of model can assume a large variance in the observed data with very little variance on the latent and expected data scales. For example, a Poisson/log GLMM with a latent mean and a total latent variance of 0.5 will result in observed data with a variance Less than half of this variance lies in the expected data scale (); the rest is residual Poisson variation. Our model hence assumes that more than half of the measured variance comes from totally random noise. Hence, even assuming that the whole latent variance is composed of additive genetic variance, the heritability will never reach a value >0.5. Whether this random noise should be accounted for when computing heritabilities (i.e., whether we should compute or ) depends on the evolutionary question under study. In many instances, it is likely that natural selection will act directly on realized values rather than their expectations, in which case should be preferred. We recommend however, that, along with , all other variances (including , and ) are reported by researchers.
The expressions given here for quantitative genetic parameters on the expected and observed data scales are exact, given the GLMM model assumptions, in two senses. First, they are not approximations, such as might be obtained by linear approximations (Browne et al. 2005). Second, they are expressions for the parameters of direct interest, rather than convenient substitutes. For example, the calculation (also suggested by Browne et al. 2005) of variance partition coefficients (i.e., intraclass correlations) on an underlying scale provides only a value of the broad-sense heritability (e.g., using the genotypic variance arising from additive genetic effects on the latent scale).
Acknowledgments
We thank Kerry Johnson, Paul Johnson, Alastair Wilson, Loeske Kruuk, and Josephine Pemberton for valuable discussions and comments on this manuscript. The Soay sheep data were provided by Josephine Pemberton and Loeske Kruuk and were collected primarily by Jill Pilkington and Andrew MacColl with the help of many volunteers. P.d.V. was supported by a doctoral studentship from the French Ministère de la Recherche et de l’Enseignement Supérieur. H.S. was supported by an Emmy Noether fellowship from the German Research Foundation (SCHI 1188/1-1). S.N. is supported by a Future Fellowship, Australia (FT130100268). M.M. is supported by a University Research Fellowship from the Royal Society (London). The collection of the Soay sheep data is supported by the National Trust for Scotland and QinetQ, with funding from the Natural Environment Research Council, the Royal Society, and the Leverhulme Trust.
Footnotes
Supplemental material is available online at www.genetics.org/lookup/suppl/doi:10.1534/genetics.115.186536/-/DC1.
Communicating editor: L. E. B. Kruuk

{kind=link}
{kind=link}
{kind=link}